Runtime, not just a library
Contenox API is a complete runtime environment – with API gateway, background workers, storage, and observability – not just a collection of helper functions.

Archived runtime project for sovereign GenAI applications
Contenox Runtime is a self-hostable engine for deterministic, chat-native AI applications. It orchestrated language models, tools, and business logic without giving up control over data, routing, or behaviour.
We operate a dual-license model. The kernel remains available as open-source software and can be used as a reference implementation or for experiments in AI workflow runtimes.
The Contenox Runtime API is actively maintained. This page remains as documentation and context for engineers, analysts, and curious people exploring the ideas and architecture behind the project.
A short walkthrough of the chat interface, state-machine workflows, and observability tools. The demo reflects the state of the project before it was sunset.
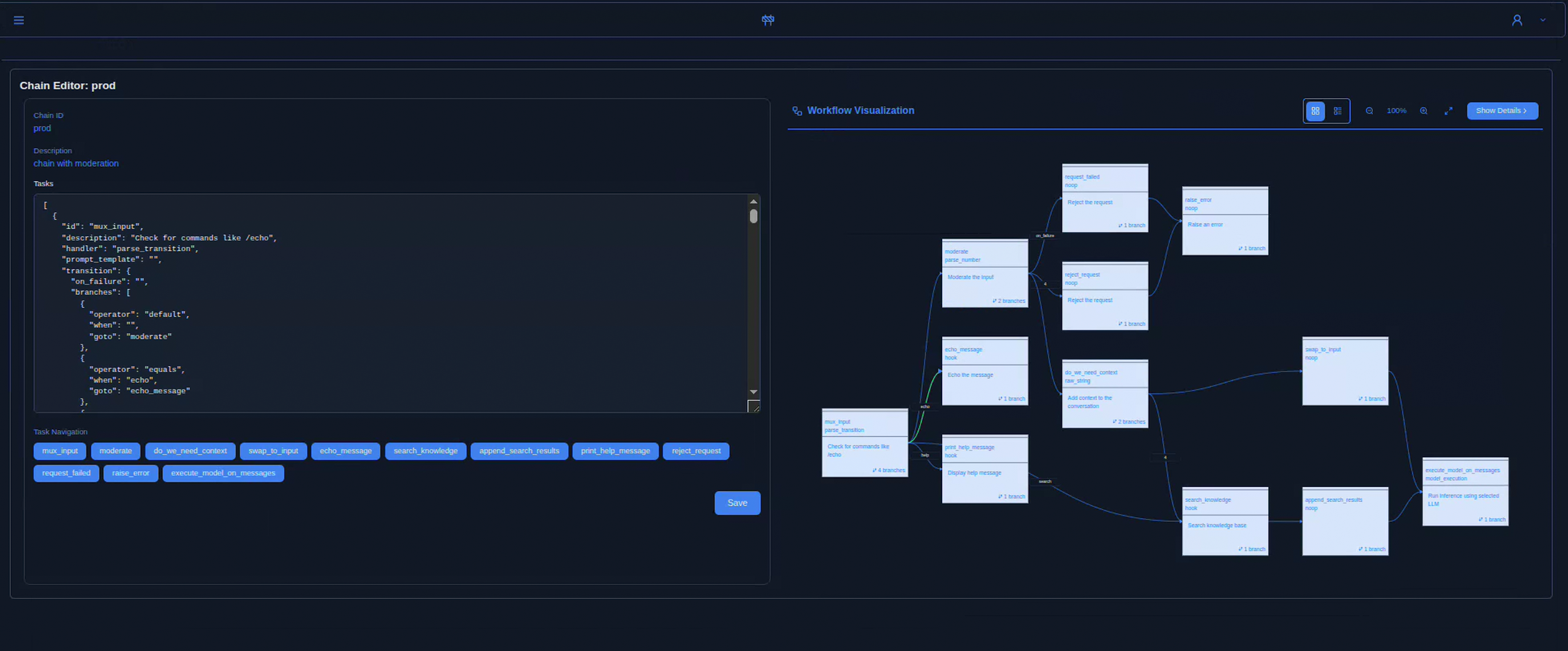
The Contenox UI combines a chat client with a visual workflow inspector and execution traces – so you can see exactly which states, tools, and hooks were involved in each conversation.
Contenox Runtime is a self-hostable engine for building and operating enterprise-grade AI agents, semantic search systems, and chat-driven applications. It modelled AI behaviour as explicit, observable state machines instead of opaque prompt chains.
Contenox API is a complete runtime environment – with API gateway, background workers, storage, and observability – not just a collection of helper functions.
Workflows were explicit graphs of tasks, handlers, and transitions. Every step was visible, controllable, and replayable.
Users interacted via chat, but under the hood each message drove a deterministic workflow – from RAG queries to tool calls and side effects.
It could run on-prem, in your cloud, or air-gapped. Requests could be routed across OpenAI, Ollama, vLLM, or custom backends without lock-in.
Even though the Contenox venture has ended, the core thesis remains relevant: modern AI systems drift into opacity. Runtimes that make logic, data flow, and side effects explicit help teams reason about behaviour instead of guessing.
The runtime was designed so teams could own data, execution, and decision boundaries – with no hidden SaaS layer that might change behaviour unexpectedly.
Workflows were deterministic state machines: tasks, transitions, retries, and human approvals were defined explicitly instead of being buried in prompts.
Every state change, model call, and hook invocation was logged and traceable – a foundation for auditing, governance, and regulation.
The Runtime API is designed to complement APIs like OpenAI’s tools or MCP. It was most useful once single AI calls turned into real workflows.
The API executes AI workflows as explicit state machines. Every step – LLM call, data fetch, or external action – was a task with defined inputs, outputs, and transitions.
Agents were extended with hooks – remote services that integrated external APIs, databases, or tools. Any OpenAPI-compatible endpoint could be registered and turned into callable tools for models.
Workflows were defined in YAML or via API. Each execution was logged and traceable: transitions, model calls, hook results, and intermediate state were all visible.
Built-in RAG pipeline with document ingestion, embeddings, and vector search (e.g. via Vald) enabled agents to answer based on your data.
Requests could be routed across Ollama, vLLM, OpenAI, or other providers, with configurable fallbacks and policies per task.
The Runtime is built as a modular, container-first system. The runtime could be embedded into existing stacks or deployed as its own AI infrastructure layer.
This is not a black-box SaaS, but software you could run and adapt – a runtime that sat between LLMs and real systems.
The core runtime engine is open-source at github.com/contenox/contenox.
View the OpenAPI specification or check the Documentation to get started with the API server.
For the CLI, visit the Contenox homepage.